Googleの特許からわかるクエリファンアウトの詳細ロジック|2つの特許を図解で解説

クエリファンアウトの技術的な仕組みは、Googleが公開した2つの特許文書から読み解くことができます。
1つ目のUS20240289407A1「Prompted Expansion」はユーザーのクエリをサブクエリに分解するプロセスを、2つ目のUS12158907B1「Thematic Search」は検索結果をテーマ別に構造化して提示するプロセスを記述しています。
SEO業界では「クエリファンアウト」という概念が広まりつつありますが、その技術的な根拠を特許レベルで解説した記事はほとんどありません。
本記事では、2つの特許の核心部分を図解で解説し、AIO(AI Overviews)やAI Modeに引用されるための条件を技術的な根拠に基づいて考察します。
なお、当社(はちのす制作)では、これらの特許の記述を398キーワードの定量検証データと照合し、特許のロジックと実際の検索挙動の整合性を確認しています。
本記事では「特許に書かれていること」と「当社の分析で観測されたこと」を明確に区別して記載します。
この記事のまとめ
2つのGoogle特許の概要
- Prompted Expansion特許(US20240289407A1)は、LLMを使ってユーザーのクエリをサブクエリに分解するプロセスを記述している
- Thematic Search特許(US12158907B1)は、サブクエリの検索結果をテーマ別に分類・統合して提示するプロセスを記述している
- 2つの特許は補完関係にあり、クエリファンアウトの「情報収集」と「情報整理・提示」をそれぞれ担っている
詳細は「クエリファンアウトの技術的背景 — 2つのGoogle特許が示す仕組み」をご覧ください
SEO実務への示唆
- サブクエリのカバー範囲がAIO引用の前提条件となる。当社検証では捕捉率が23.3%から74.1%に拡大した
- Thematic Searchの「trustworthiness measure」は、ドメインの信頼性・著者の権威性・被リンクの質で構成される
詳細は「特許のロジックからわかるSEOへの示唆」をご覧ください
目次
クエリファンアウトの技術的背景 — 2つのGoogle特許が示す仕組み
クエリファンアウトの根拠となる技術は、Googleが2023年に出願した2つの特許文書で示されています。
クエリファンアウトの詳細ロジックとは、Googleが2つの特許(Prompted Expansion:US20240289407A1、Thematic Search:US12158907B1)で示した、検索クエリを自動的にサブクエリに分解・展開して情報を収集し、テーマ別に構造化して提示する技術的な仕組みのことです。
2024年5月のGoogle I/Oでは、AI Overviewsの中核技術として「query fan-out」が紹介されました。
この技術は、ユーザーが入力した1つの検索クエリに対して、AIが内部的に複数のサブクエリを生成し、それぞれのサブクエリで検索を実行した結果を統合して回答を生成する仕組みです。
この仕組みの技術的な詳細は、以下の2つの特許に記述されています。
| 項目 | Prompted Expansion(US20240289407A1) | Thematic Search(US12158907B1) |
|---|---|---|
| 正式名称 | Generating Search Queries Using a Large Language Model | Thematic Search Results |
| 出願日 | 2023年 | 2023年 |
| 担当フェーズ | 情報収集(サブクエリ生成) | 情報整理・提示(テーマ別構造化) |
| 核心技術 | LLMによるSQ/VQ 2段階生成 | セマンティック分析によるテーマ分類 |
| 主な対象 | クエリの分解・拡張 | 検索結果の統合・表示 |
2つの特許は、クエリファンアウトの異なるフェーズを担っています。
Prompted Expansionが「どのようなサブクエリを生成するか」を、Thematic Searchが「生成されたサブクエリの結果をどう整理・提示するか」を規定しています。
なお、特許に記載された技術がそのままGoogle検索に実装されているとは限りません。
ただし、Google公式ドキュメントでもAI OverviewsとAI Modeが「query fan-out技術を使用する」と明記されており、特許の記述と公式発表の内容には高い整合性が認められます。
関連記事:クエリファンアウトとは? Google検索が質問を分解して調べる仕組みとSEOへの影響
参考記事:Google|Generative AI in Google Search: May 2024 update
参考記事:Google Patent|US20240289407A1 Generating Search Queries Using a Large Language Model
参考記事:Google Patent|US12158907B1 Thematic Search
特許①:Prompted Expansion — クエリをサブクエリに分解する仕組み
Prompted Expansion特許(US20240289407A1)は、LLMに対して構造化されたプロンプトを与えることで、ユーザーのクエリを複数のサブクエリに自動分解するプロセスを記述しています。
この特許の核心は「LLMに何を指示してサブクエリを生成するか」にあります。
単に「関連するクエリを生成せよ」という汎用的な指示ではなく、具体的な生成軸を明示的に指定することで、質の高いサブクエリ群を生成する仕組みです。
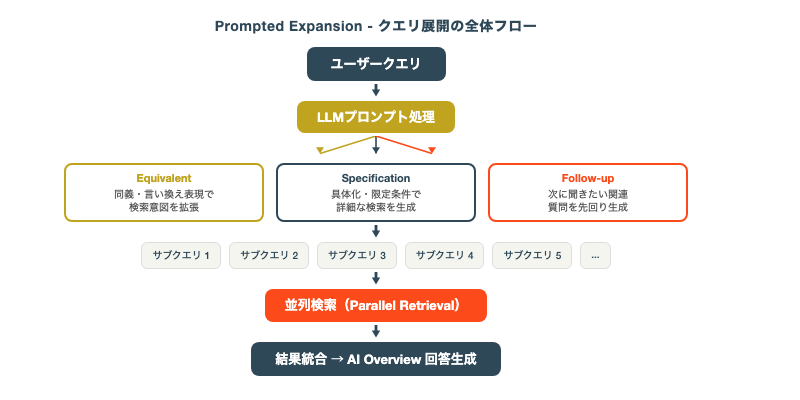
サブクエリの生成ロジック — LLMがクエリの意図を多角的に展開する
特許の記述内容を分析すると、サブクエリ生成のロジックは以下の3つの軸で整理できます(分類名称は当社の分析による便宜的なものであり、特許原文の用語ではありません)。
- 意図の多様性(当社分類):リードクエリに含まれる複数の検索意図を分解します。たとえば「クエリファンアウト とは」というクエリには、「定義を知りたい」「仕組みを理解したい」「SEOへの影響を知りたい」など複数の意図が含まれています。特許では、これらの意図をそれぞれ独立したサブクエリとして生成するプロセスが記述されています
- 語彙のバリエーション(当社分類):同じ意図を異なる言葉で表現します。「クエリファンアウト」の言い換えとして「query fan-out」「クエリ展開」「検索クエリ拡張」などを生成します。これにより、表記揺れや同義語を含むWebページも検索対象に含めることができます
- エンティティベースの再構成(Entity-based Reformulation):リードクエリに含まれるエンティティ(固有名詞や概念)を軸に、関連するクエリを構成します。たとえば「Google検索」「AI Overviews」「Gemini」などのエンティティから派生するクエリを生成します
特許が記述するサブクエリの生成は、2段階で行われます。
第1段階では、リードクエリからSQ(Sub Query)を生成します。
SQはリードクエリから派生する異なる検索意図を持つクエリです。
第2段階では、各SQに対してVQ(Variant Query)を展開します。
VQはSQの言い換えや表記揺れです。
当社のファンアウト分析で観測されたVQタイプ(equivalent=言い換え、specification=詳細化、follow_up=深掘り等)は、この特許が記述する3つの生成軸と整合しています。
ただし、VQタイプの分類名称は当社が分析上の便宜のために付けたものであり、特許にこれらの名称が記載されているわけではありません。
並列検索と結果の統合 — サブクエリごとに最適なソースを選ぶ
特許では、生成されたサブクエリがそれぞれ独立に検索エンジンに投入されると記述されています。
各サブクエリは並列に処理され、それぞれの検索結果から関連性の高いドキュメントが収集されます。
この並列処理が「ファンアウト(fan-out=扇状に広がる)」という名称の由来です。
1つのクエリが複数のサブクエリに「扇状に広がり」、それぞれが独立に検索を実行する構造になっています。
収集された検索結果は、最終的にLLM(Gemini)によって統合され、AIOの回答として生成されます。
この統合プロセスの詳細は、次のThematic Search特許で記述されています。
参考記事:Google Patent|US20240289407A1 Generating Search Queries Using a Large Language Model
特許②:Thematic Search — 検索結果をテーマ別に構造化する仕組み
Thematic Search特許(US12158907B1)は、複数のサブクエリから収集された検索結果を、テーマ(トピック)ごとに分類・統合し、構造化された回答として提示するプロセスを記述しています。
Prompted Expansionが「情報の収集」を担うのに対し、Thematic Searchは「情報の整理と提示」を担います。
この特許が記述する処理は、クエリファンアウトの「後半」に相当します。

テーマ分類のロジック — 検索結果をサブトピックに自動分類する
特許では、収集された検索結果をセマンティック(意味的)に分析し、関連するテーマにグルーピングするプロセスが記述されています。
たとえば「クエリファンアウト とは」というクエリに対するサブクエリ群の検索結果は、「定義・基本概念」「技術的な仕組み」「SEOへの影響」「具体的な対策方法」などのテーマに自動分類されます。
各テーマに対して、最も関連性の高い検索結果(URL)が選定されます。
このテーマ別のURL選択は重要なポイントです。
あるテーマには技術解説に強いサイトが、別のテーマにはデータ分析に強いサイトが選ばれるため、1つのサイトがすべてのテーマで引用されることは稀です。
この構造が、トピッククラスター戦略(メイン記事+テーマ別のクラスター記事)の有効性を技術的に裏付けています。
信頼度スコア(trustworthiness measure)の仕組み — どのソースが引用されるかを決める要素
特許では、テーマごとに選定されたURLの優先順位を決める指標として「trustworthiness measure(信頼度指標)」に言及しています。
特許の記述によると、この指標は以下の要素で構成されます。
- ドメインの信頼性:ドメインがどの程度信頼できるソースであるか
- 著者の権威性:コンテンツの著者がその分野でどの程度の専門性・権威を持つか
- 被リンクの質:他の信頼できるサイトからどの程度参照されているか
ここで注意すべき点があります。
特許が言及する「trustworthiness measure」は、Ahrefsが算出するDR(Domain Rating)やMozが算出するDA(Domain Authority)とは異なるものです。
DRやDAはサードパーティツールが独自に算出する指標であり、Googleの内部スコアとは別の評価軸です。
ただし、特許が示す信頼度スコアの構成要素(ドメインの信頼性・著者の権威性・被リンクの質)は、GoogleがE-E-A-T(経験・専門性・権威性・信頼性)として公開している品質評価の考え方と整合しています。
特許は、E-E-A-Tの考え方が技術的にどのように実装されうるかを示唆するものといえます。
参考記事:Google Patent|US12158907B1 Thematic Search
参考記事:Google Search Central|AI Overviews and your website
特許のロジックからわかるSEOへの示唆 — AIOに引用されるための条件
2つの特許の技術的ロジックから逆算すると、AIOやAI Modeに引用されるためには「サブクエリのカバー範囲」と「信頼度スコア」の2つが重要な条件であることがわかります。
ここからは、特許の記述に基づく技術的な示唆と、当社の検証データで観測された結果を組み合わせて考察します。
特許に書かれている内容と、当社の分析結果は明確に区別して記載します。
示唆①:サブクエリのカバー範囲がAIO引用の前提条件
Prompted Expansion特許のロジックに基づくと、AIOの回答はサブクエリごとに収集された検索結果から構成されます。
つまり、自社サイトがサブクエリの検索結果に表示されていなければ、そもそもAIOの引用候補に入りません。
当社が398キーワード(約18,870クエリ)を対象に実施した定量検証では、従来のSEO分析(メインキーワード+サジェスト)での捕捉率は23.3%でした。
一方、ファンアウト分析でサブクエリ(SQ・VQ)まで分析範囲を広げた場合、捕捉率は74.1%に拡大しました(差分+50.8ポイント、Wilcoxon検定 p<0.001)。
この結果は、Prompted Expansion特許が記述するサブクエリ生成の仕組みと整合しています。
特許が示す3つの生成軸(意図の多様性・語彙のバリエーション・エンティティベースの再構成)に対応する形で記事を設計することが、AIO引用の前提条件であると考えられます。
また、当社のVQタイプ別分析では、equivalent(言い換え)型が最も捕捉率拡大に寄与し(効率性0.342/VQ)、equivalentとspecification(詳細化)の2タイプで全体の約80%をカバーできることがわかっています。
AIOに限定すると、specificationの寄与がさらに高くなる傾向(16.8%から21.4%)も観測されました。
示唆②:信頼度スコアが引用の優先順位を決める
Thematic Search特許が言及する「trustworthiness measure」は、サブクエリの検索結果の中からどのURLを引用するかの優先順位を決定する要素です。
特許の記述に基づくと、信頼度スコアはドメインの信頼性・著者の権威性・被リンクの質で構成されます。
これは、Google Search Centralが公開しているAI Overviewsに関するドキュメントで述べられている「AI OverviewsはGoogleの検索品質システムと同じ基準でソースを評価する」という記載と整合しています。
SEO実務への具体的な示唆としては、以下の3点が挙げられます。
- 一次データの提供:独自の調査データや検証結果を含むコンテンツは、特許が示す信頼度スコアの向上に寄与すると考えられます。二次情報の再編集よりも、一次情報の提供が有利です
- 著者情報の明示:特許が著者の権威性に言及していることから、記事の著者情報(専門性・実績)を明示することが引用の優先順位に影響する可能性があります
- テーマ別の専門性構築:Thematic Searchのテーマ別URL選択ロジックに基づくと、特定のテーマに対する専門性を示すコンテンツ群(トピッククラスター)を構築することが有効です
関連記事:クエリファンアウトとは? Google検索が質問を分解して調べる仕組みとSEOへの影響
関連記事:クエリファンアウトのデメリット
参考記事:Google Search Central|AI Overviews and your website
特許を理解してクエリファンアウト時代のSEO戦略を組み立てる
Googleの2つの特許は、クエリファンアウトの内部ロジックを理解するための最も信頼性の高い一次情報源です。
本記事で解説した内容を整理します。
- Prompted Expansion特許(US20240289407A1)は、LLMを使ってユーザーのクエリをサブクエリに分解するプロセスを記述しています。意図の多様性・語彙のバリエーション・エンティティベースの再構成という3つの軸でサブクエリが生成されます
- Thematic Search特許(US12158907B1)は、サブクエリの検索結果をテーマ別に分類・統合して提示するプロセスを記述しています。各テーマの信頼度スコア(trustworthiness measure)に基づいて引用URLが選定されます
- 2つの特許の組み合わせにより、「どのようなサブクエリが生成され、どのように検索結果が統合されるか」という、クエリファンアウトの全体像を理解できます
特許に書かれた技術的なロジックを理解することで、「なぜトピッククラスター戦略が有効なのか」「なぜ一次データの提供が重要なのか」といったSEO施策の根拠を、推測ではなく技術的な裏付けをもって説明できるようになります。
関連記事
-
 クエリファンアウトのデメリットとは? CTR低下・ゼロクリック検索がサイト運営者に与える影響【2026年最新】
クエリファンアウトのデメリットとは? CTR低下・ゼロクリック検索がサイト運営者に与える影響【2026年最新】 -
 サジェストキーワード・再検索キーワード・クエリファンアウトの違いとは? 3つの概念を徹底比較
サジェストキーワード・再検索キーワード・クエリファンアウトの違いとは? 3つの概念を徹底比較 -
 クエリファンアウトとは? Google検索が質問を分解して調べる仕組みとSEOへの影響【2026年最新】
クエリファンアウトとは? Google検索が質問を分解して調べる仕組みとSEOへの影響【2026年最新】 -
 AI Overviewsとは? CTR最大58%低下時代のSEO対策【2026年最新】
AI Overviewsとは? CTR最大58%低下時代のSEO対策【2026年最新】 -
 【独自調査】検索行動の「二段階化」とは? 15,000人調査で見えた生成AI時代のSEO戦略
【独自調査】検索行動の「二段階化」とは? 15,000人調査で見えた生成AI時代のSEO戦略 -
 LLMO時代の広報戦略とは?AIに正しく理解されるエンティティ設計の考え方
LLMO時代の広報戦略とは?AIに正しく理解されるエンティティ設計の考え方 -
 “とりあえずChatGPT”が新常識に──業務で生成AIを使った検索、決裁層の6割超が経験
“とりあえずChatGPT”が新常識に──業務で生成AIを使った検索、決裁層の6割超が経験 -
 AI流入の確認方法|ChatGPT・Geminiなどからのアクセスを可視化する方法3選
AI流入の確認方法|ChatGPT・Geminiなどからのアクセスを可視化する方法3選